Unsupervised Learning of 3D Shapes from Single Images
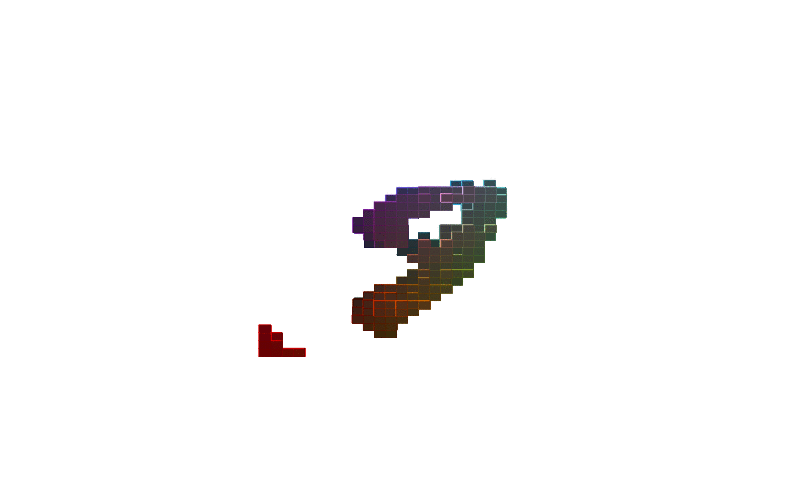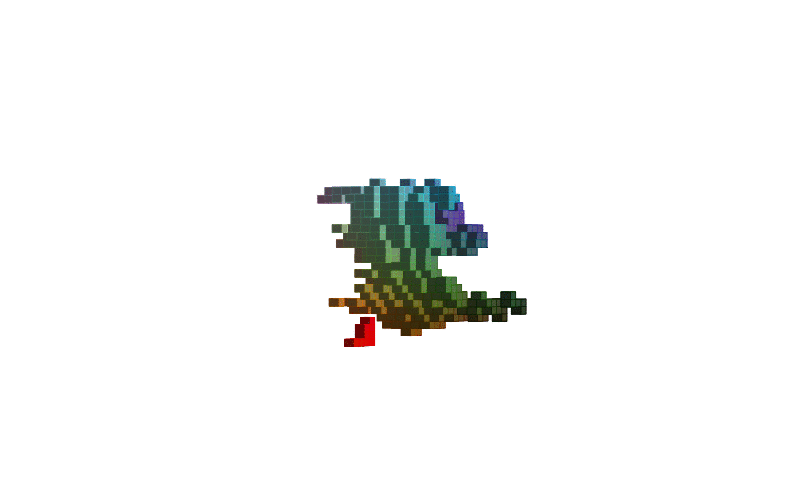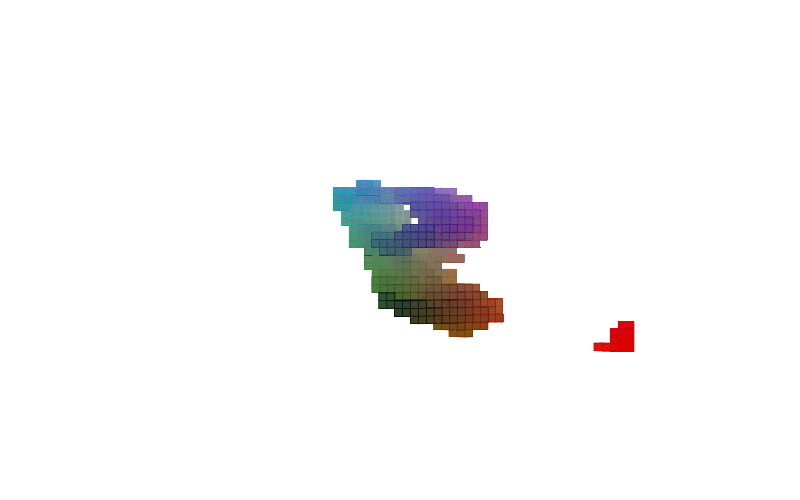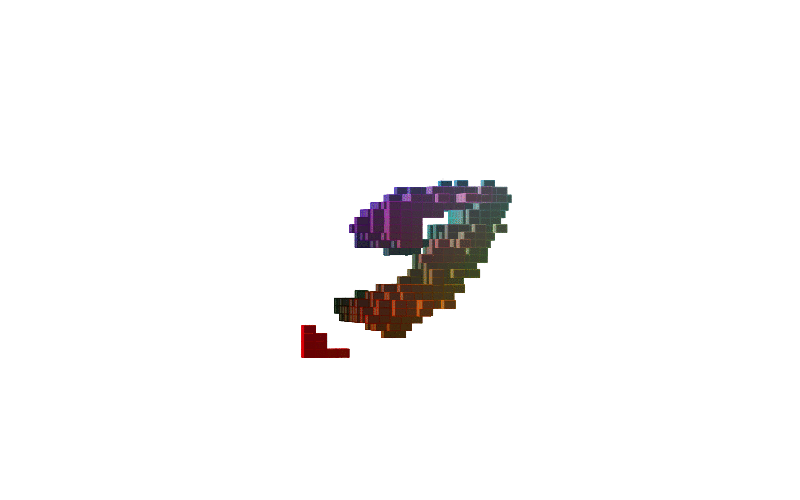
Paper: Unsupervised learning of 3D shapes from single images
Github page for this project: 3D-VAE, named uVAE, project page
Abstract from the paper:
Using generative models for Inverse Graphics is an active area of research. However, most works focus on developing models for supervised and semi-supervised methods. In this work, we study the problem of unsupervised learning of 3D geometry from single images. Our approach is to use a generative model that produces 2-D images as projections of a latent 3D voxel grid, which we train either as a variational auto-encoder or using adversarial methods. This post looks into how we can recover 3D shape and pose from general datasets such as MNIST, and MNIST Fashion in good quality, basen on the paper, Unsupervised learning of 3D shapes from single images, and exhibits some of the results obtained during training to be complementary to the paper. You can find the more details in the paper.
3D VAE Architecture:
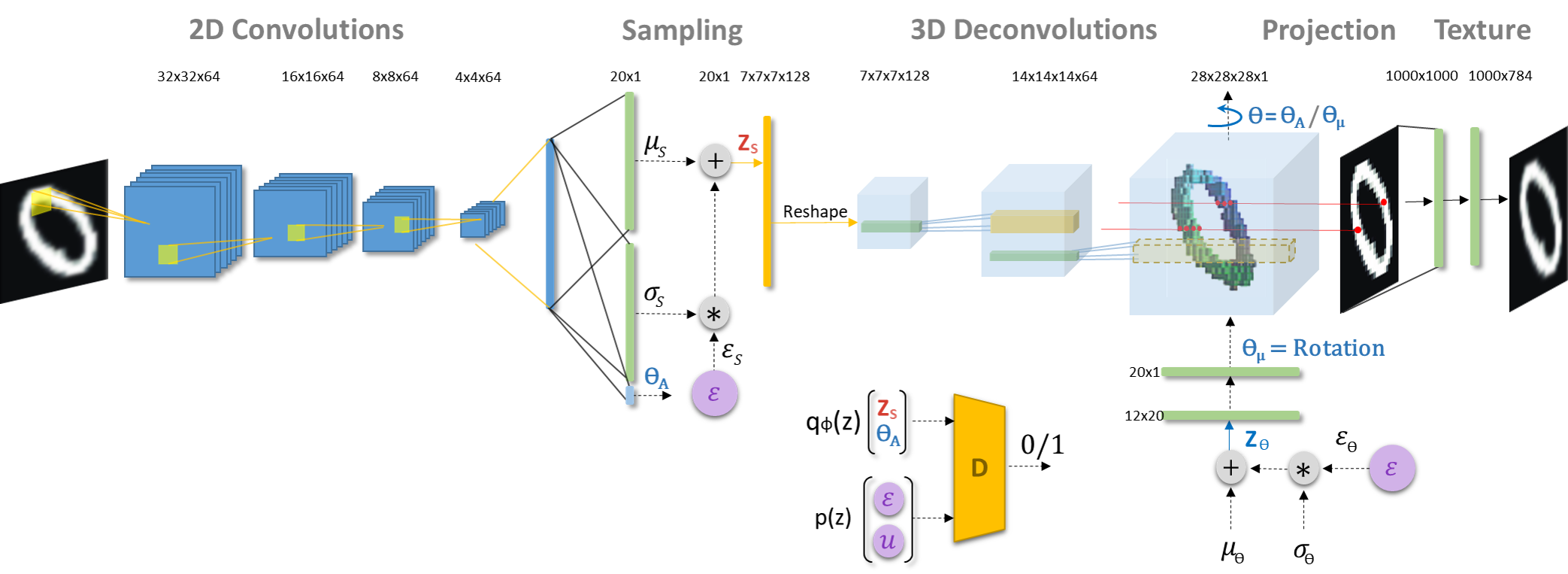 Figure-1
Figure-1
Learning 3D shapes from MNIST and MNIST Fashion during training:
Figure-1 shows how 3D shapes are learned during training while Figure-2 lists renderings of these 3D shapes. It should be noted that only MNIST and MNIST Fashion items are shown although the model is trained on a dataset consisting of a mixture of MNIST, MNIST Fashion, CelebA, and some categories of ModelNet40. That’s why we see human faces in rendered images in the initial part of the training.











 Figure-1: 3D shapes of digits and fashion items learned during training. From top to bottom, the shapes are the digits 0, 2, 2, 3, 5, 6, 7, 8, 9 and the fashion items pants, shirt and shoe.The model is trained on a combined datasets consisting of MNIST, MNIST Fashion, CelebA, and several categories of ModelNet40.
Figure-1: 3D shapes of digits and fashion items learned during training. From top to bottom, the shapes are the digits 0, 2, 2, 3, 5, 6, 7, 8, 9 and the fashion items pants, shirt and shoe.The model is trained on a combined datasets consisting of MNIST, MNIST Fashion, CelebA, and several categories of ModelNet40.
360 view of MNIST Digits:
| Digit 0 | Digit 8 | Digit 9 |
|---|---|---|
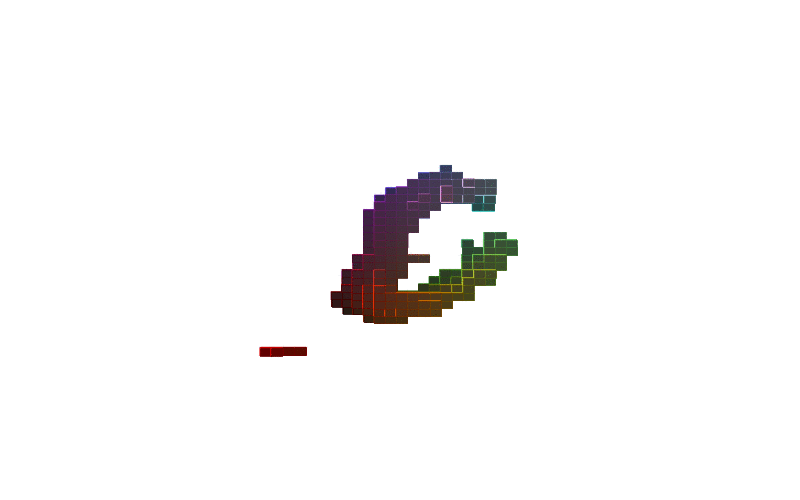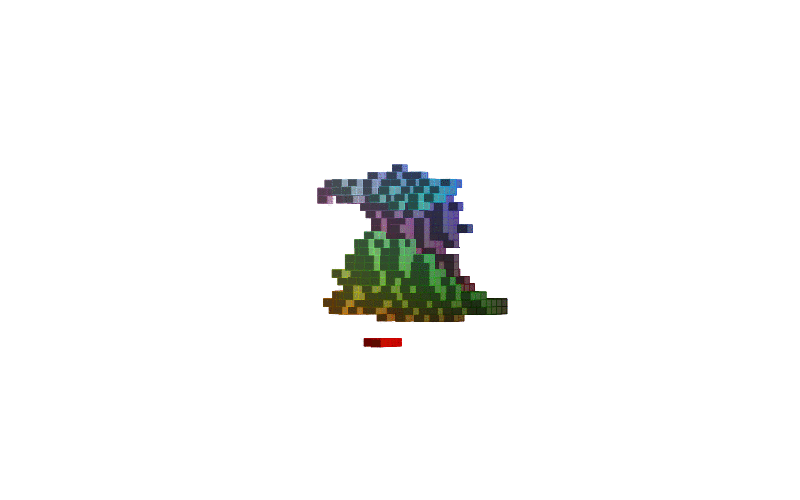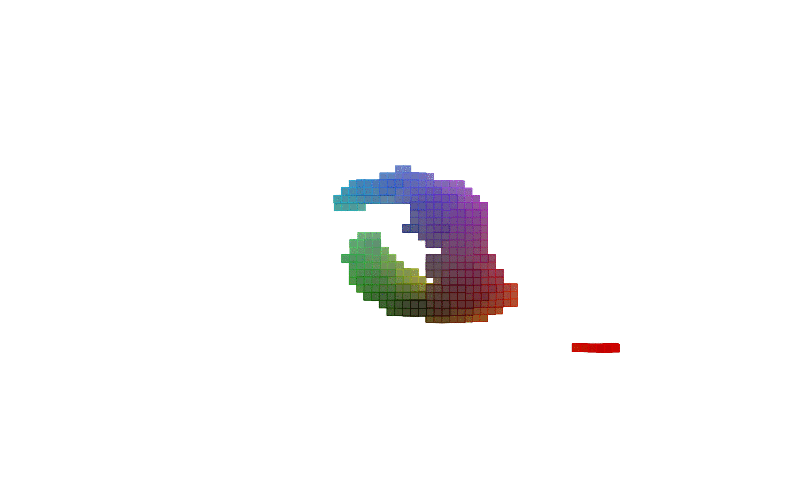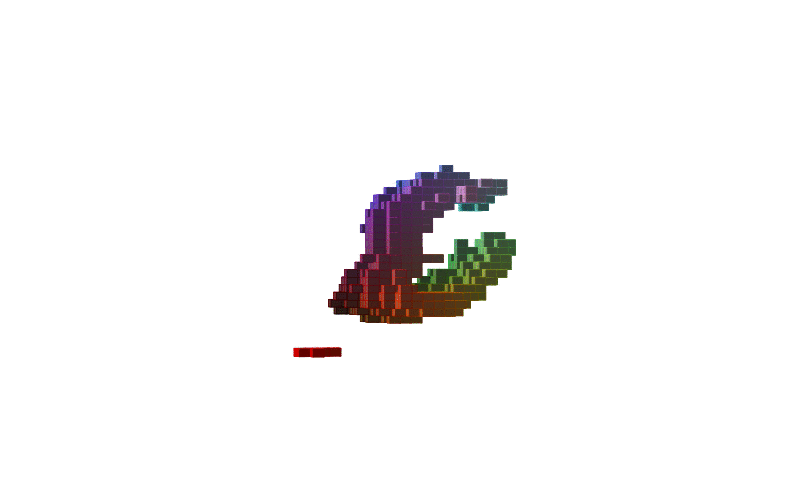 |
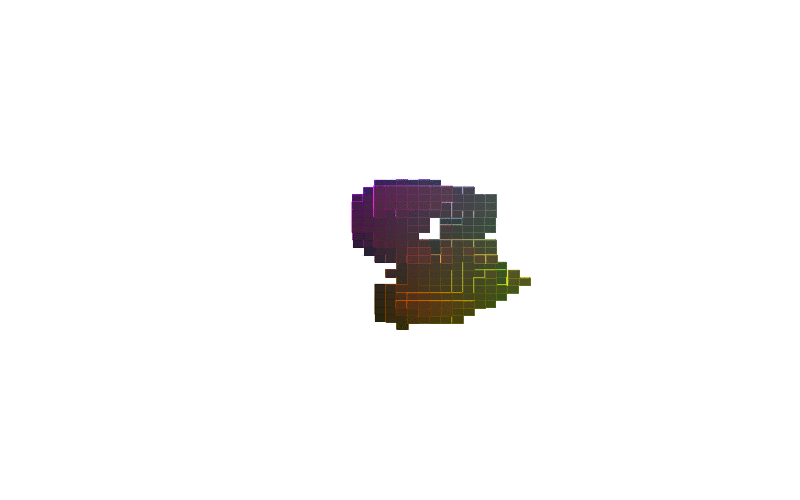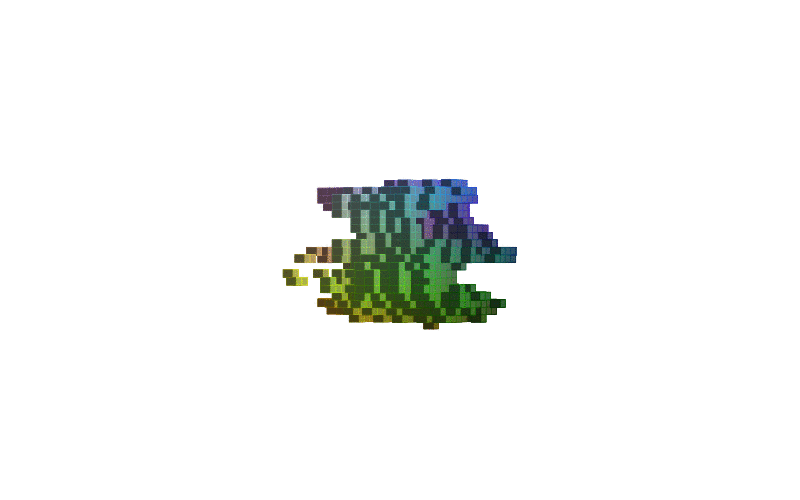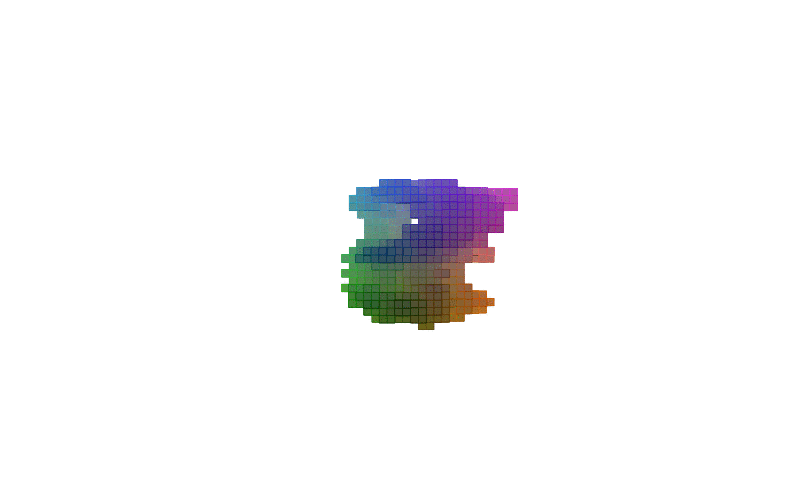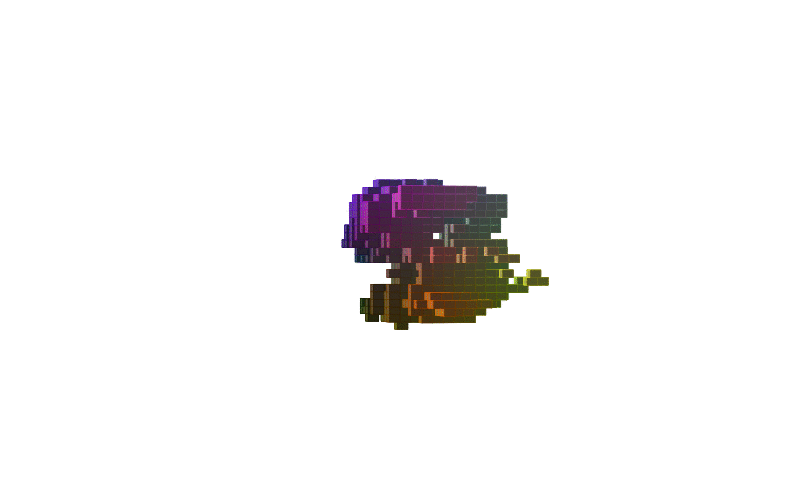 |
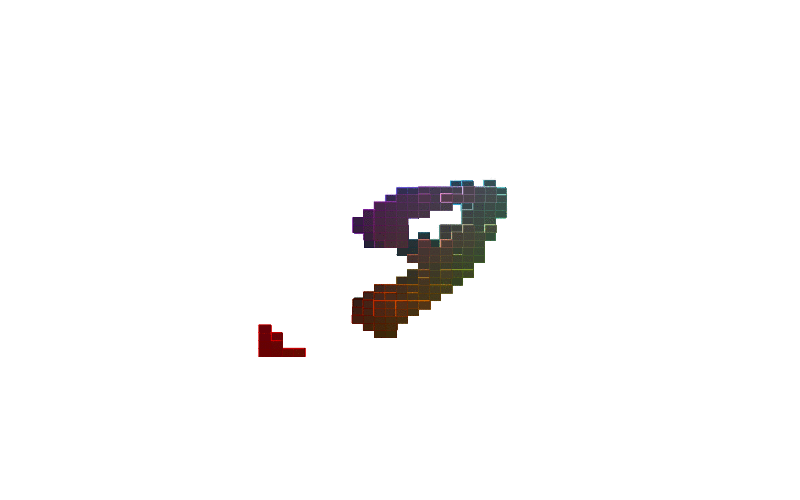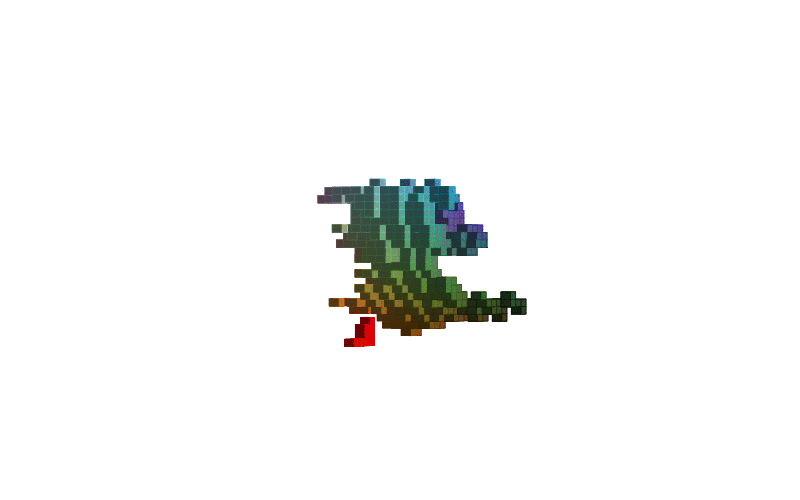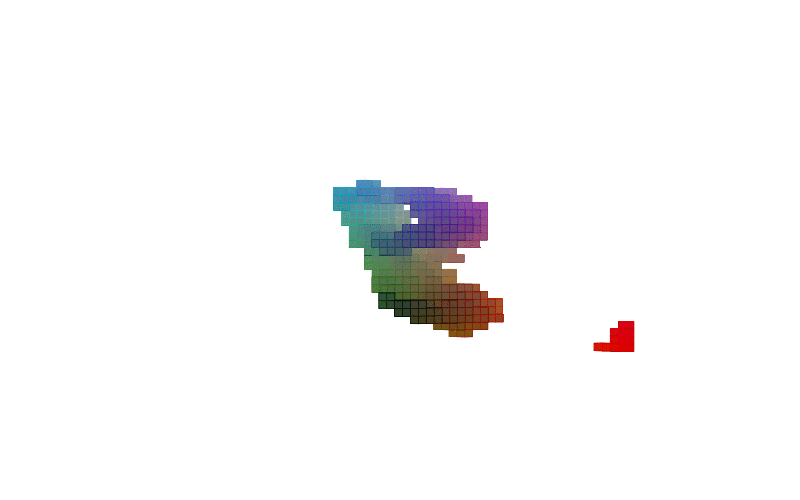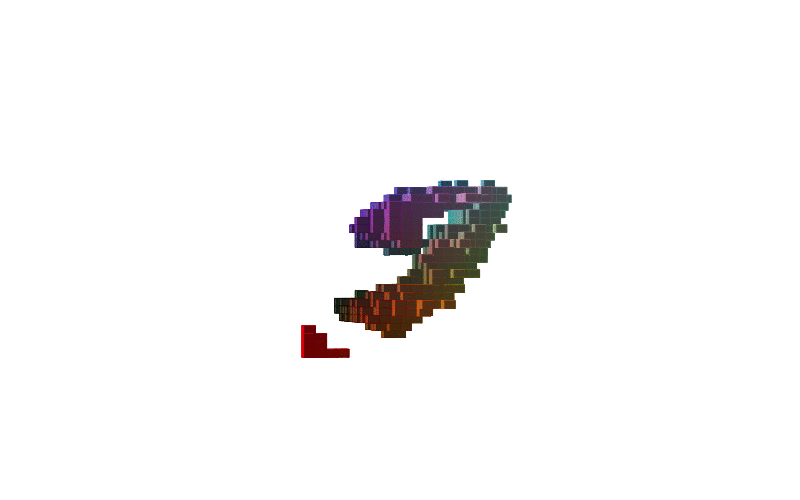 |
Figure-2: 360 view of inferred shapes for MNIST digits 0, 8 and 9.
Input data and renderings from inferred 3D shapes:
| Input Data | Rendered images during training |
|---|---|
 |
 |
 |
 |
Figure-3: Rendering of 3D shapes learned during training. The model is trained on a combined datasets consisting of MNIST, MNIST Fashion, CelebA, and several categories of ModelNet40.
Learning 3D shapes from CelebA dataset:
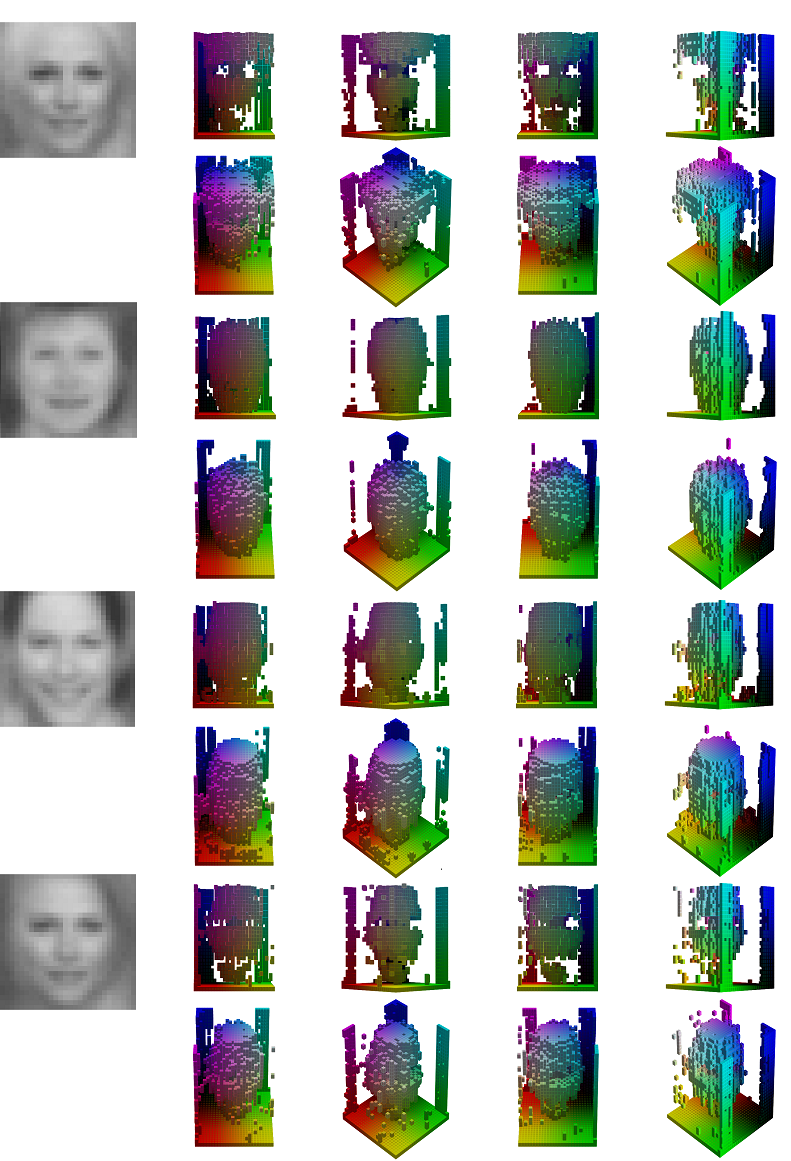
Figure-4: Closer look at 3D shapes learned from CelebA during training. In this example, 3D-VAE is trained on CelebA dataset separately rather than combined dataset.
Textured rendering of items from ModelNet40:
| Input Data | Output at Projection Layer | Output at Texturizer |
|---|---|---|
 |
 |
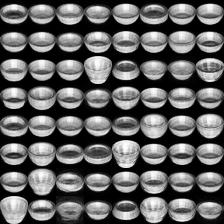 |
 |
 |
 |
Figure-5: Quality of renderings at the texture layer for Bowl (top) and Person (bottom) categories of ModelNet40. In this case, 3D-VAE is trained on individual datasets separately rather than combined dataset.
Conclusion:
This paper shows possible ways to learn 3D geometry from single images, and showcases its results using MNIST, MNIST Fashion, and CelebA datasets, in each of which there is a single view for each object. For more details, you can read the paper here: Unsupervised learning of 3D shapes from single images